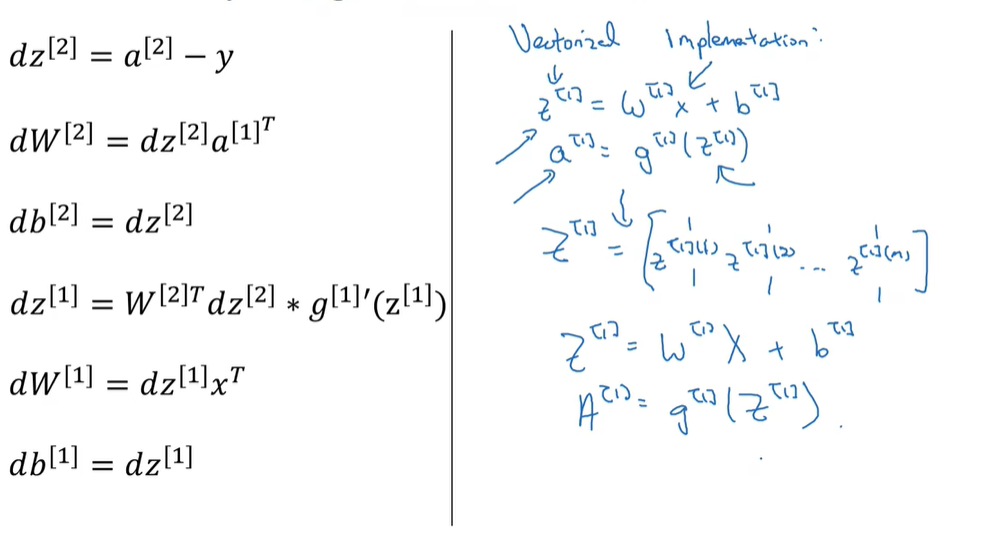33.神经网络的梯度下降法
33.1 Gradient descent for neural networks
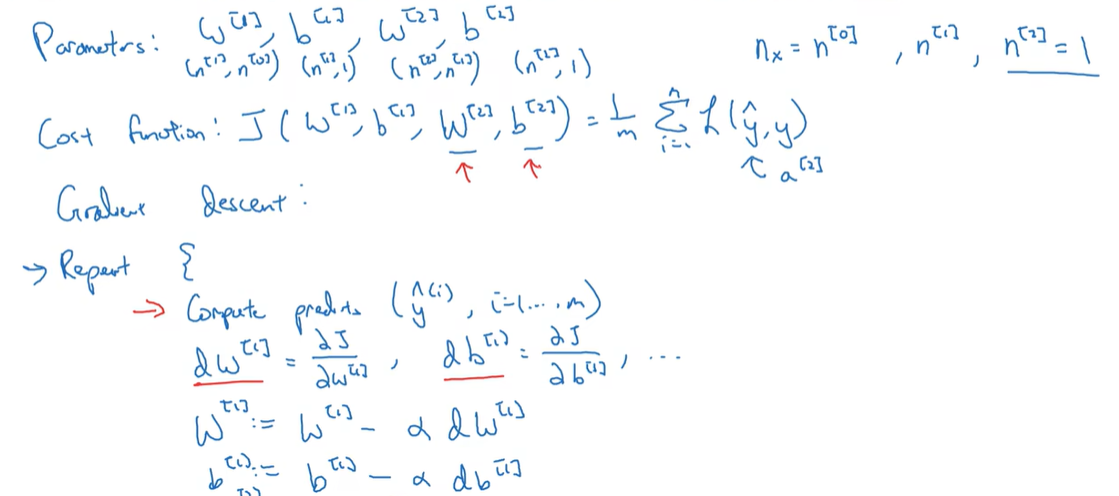
33.2 Formulas for computing derivatives

33.3 Computing gradients

这里迷糊了好久,终于理清楚了:P20 2.14证明了$dw=xdz^T$,这里写成了dw=dzx,实际上效果一样,对于矩阵相乘来说,左右互换结果就不一样了,dz写在前面,等同做了一次转置
〖(A∗B)〗^T=B^T∗A^T

33.4 Summary of gradient descent